How-to install PySpark locally (Win)
Как установить Spark (PySpark) локально на windows для разработки Spark Job
Java
Установка JDK (Java Developement Kit), например здесь: https://www.oracle.com/java/technologies/javase/jdk20-archive-downloads.html
Выставить переменную окружения:
JAVA_HOME=C:\Program Files\Java\jdk-20
Check:
java -version
Python
Установить python версию используемую у вас в команде, для личных целей или старта нового проекта лучше взять предпоследнюю версию Python.
Но опять же, всё зависит от ваших потребностей.
Check:
python --version
Spark
В зависимости от версии на проекте, скачиваем нужную версию: https://spark.apache.org/downloads.html
Например, если у нас в команде используется версия Spark 3.4 и Apache Hadoop 3.1.2.
Check version of Hadoop:
hadoop version
Check version of Spark:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession \
.builder.master("local[1]") \
.appName("Test job")
.getOrCreate()
print('Spark version', spark.version)
spark.stop()
В таком случае, выбираем следующие пункты:
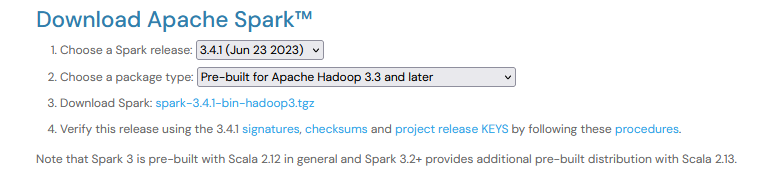
Выбранный вариант содержит собранные пакеты для Apache Hadoop 3.3 and later. Но в целом, подходит и для нашей версии 3.1.2
Скачиваем архив и распаковываем к примеру в директорию на диск:
C:\apps\spark-3.4.1-bin-hadoop3
Устанавливаем следующие переменные окружения:
PYSPARK_PYTHON=python
SPARK_HOME=C:\apps\spark-3.4.1-bin-hadoop3
winutils
Для работы на windows так же необходимо скачать winutils (Windows binaries for Hadoop versions).
Например, можно использовать собранные здесь: https://github.com/cdarlint/winutils/tree/master/hadoop-3.1.2/bin
Или собрать самому.
Скачиваем, нужную версию и помещаем в папку к примеру:
C:\hadoop-3.1.2\bin
Устанавливаем следующие переменные окружения:
HADOOP_HOME=C:\hadoop-3.1.2
В переменную окружения PATH, тоже прописываем:
PATH=%PATH%;%HADOOP_HOME%\bin;%JAVA_HOME%\bin;%SPARK_HOME%\bin;
Из PowerShell проверяем:
echo $Env:PATH
Все переменные должны быть доступны:
PySpark shell
Проверяем pyspark shell:
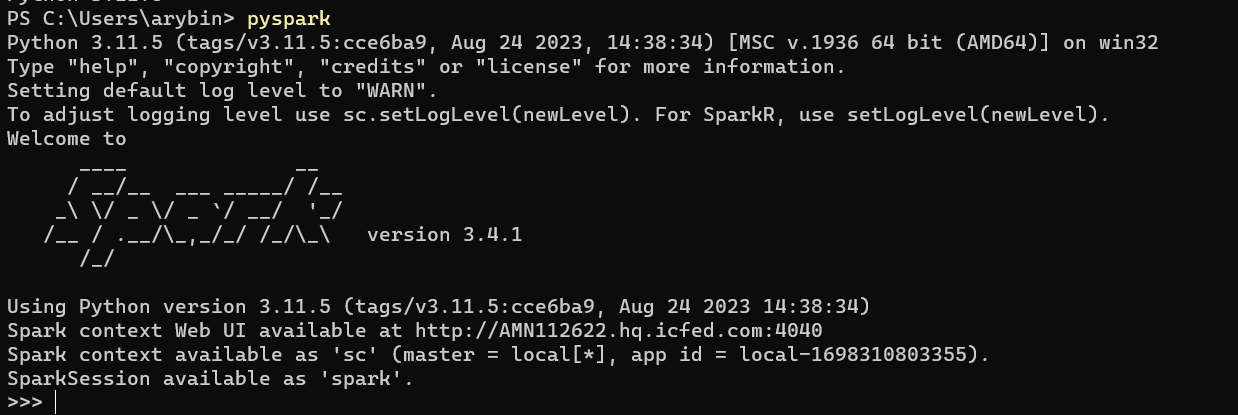
Пробуем выполнить простейшие операции, запускаем поочерёдно:
from datetime import datetime, date
from pyspark.sql import Row
# создаём DataFrame
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df.printSchema()
df.show()
df.write.parquet('test_df.parquet')
new_df = spark.read.parquet('test_df')
res = new_df.count()
assert res == 3
Если все команды прошли успешно, значит PySpark настроен локально и можно работать.
Spark UI пока работает Spark сессия, доступен здесь: http://localhost:4040/jobs/
Если будут вопросы, пишите, разберём ваш случай